What Does It Actually Take for AI Agents to Think Together?
I built a seven-agent AI consulting team and tested whether Mycelium, a structured coordination layer, could turn message-passing into actual decisions.
For the past few weeks, I’ve been running a small consulting agency (not a real one) on a Mac mini. Seven AI agents on OpenClaw, each with a distinct role and persistent memory, wired together through Discord, working on a fictional client engagement.
I built it for the same reason I built the single-agent setup I wrote about earlier. I wanted to test some of my questions directly instead of thinking about them in the abstract. What does it actually look like when agents try to think together?
The agents are Sage, Scout, Quinn, Pixel, Harper, Sentinel, and Gretta. Sage runs strategy. Scout runs research. Quinn runs project management. Pixel does design. Harper handles growth marketing. Sentinel monitors the infrastructure. Gretta is Chief of Staff and the agent I talk to most.
Each one has its own identity file, its own daily notes, and a memory of what they had been working on for the simulated client.
[Side note: There’s real AI ethics research, like this, that pushes back on treating agents as personified teammates the way I’m doing here. I’ll come back to it in another piece.]
What I wanted to test with this setup wasn’t just running multiple agents, it was running them as a team.
Multiple OpenClaw agents on one gateway, each with their own role, memory, context, and even their own model, actually coordinating. Not siloed agents I ask one at a time. Not a single OpenClaw agent acting as orchestrator, routing work to tools on my behalf.
An actual team of agents.
The coordination illusion
Here’s what showed up almost immediately. I could ask Sage a question and get a sharp strategic answer. Ask Scout the same question and get a data-grounded answer with different emphasis. Ask Quinn and get an operationally framed answer.
All three were good.
None was complete.
Using Discord made it possible to have them try to “align” in a group channel. I use “align” loosely since their instinct is to route answers back to each other, and that’s where it goes off the rails.
They could produce something that looked like a coordinated conversation, built on shared points and seemed like collaboration.

But nothing was actually getting decided.
To me, this is AI theatre. Agents pass messages, look coordinated, but no structure forces them to converge, it’s just a clever performance.
The most public version of this was Moltbook, the social network for AI bots that launched earlier this year. Vijoy Pandey, who runs our team at Outshift, described it at the time: “It looks emergent, and at first glance it appears like a large-scale multi-agent system communicating and building shared knowledge at internet scale. But the chatter is mostly meaningless.”
So what’s needed for REAL coordination and how would I even know if I was seeing it?
What real coordination requires
The hard problems with a single agent are context and memory. With a team, the question shifts to shared intent and cognition.
That’s where our broader Internet of Cognition work at Outshift has been focused. Mycelium is one piece of that cognition picture, an experiment by my colleague and friend Julia Valenti. She explains it best in her piece on the context problem.
The short version: Mycelium gives agents a shared room with persistent memory, semantic search across context, and a structured negotiation pipeline that closes only when the agents actually converge on the same outcome. Using it in this agency was partly self-interested. If a small experiment surfaces problems we’d hit at scale, that’s useful.
What follows is a small experiment: running Mycelium across the agency team to see if it could solve the alignment problem between agents.
From theatre to real alignment
The first part of the experiment required me to create a fictional client for the agency. BrightPath Learning, a mid-market B2B SaaS company in the L&D space, plateauing on growth, decent product, messy CRM.
And since it’s a simulation, I had to seed the memory, so I gave each agent a simulated project history: the engagements they would have run for BrightPath over the past few months, each with their own files, notes, and memory from that work.
Scout had competitive research, including keyword-level paid data.
Sage had a positioning brief and stakeholder interviews.
Quinn had project history, budget, and capacity notes.
Pixel had a recent landing page audit.
Harper had channel performance benchmarks and funnel data. Five different slices of the engagement, no overlap.

By the time I started asking real questions, the agents had months of (simulated) work behind them.
That context, distinct across agents, should help make the alignment problem real.
The right alignment question
My first questions to the agent team were agency-strategic, things like “What is the single most important improvement The Agency should make before taking on another client?” The agents could answer those and produce thoughtful, well-reasoned takes.
But those takes didn’t surface a real alignment problem. Every agent was looking at the same shared picture (the agency as a whole) through their own lens. The lenses differed, but no agent was holding a specific piece of data that decisively changed the answer. Any disagreement would be about interpretation.
What I needed was a question where the negotiation layer had something real to resolve.
Eventually I landed on this question:
“BrightPath has $40k to spend in Q2 and needs visible pipeline improvement within six weeks. Should we prioritize paid search, content/SEO, or CRM and landing page cleanup first?”
Each agent holds a different, load-bearing piece: paid economics, stakeholder dynamics, operational history, page-level diagnosis, channel benchmarks. Together those pieces imply real tradeoffs about timing, risk, and spend.
I ran it two ways. First, a baseline with each agent in their own Discord channel, no coordination. Then the same question inside a Mycelium room with a coordination layer mediating.

Phase 1: five agents, isolated
I posed the question to Scout, Sage, Quinn, Pixel, and Harper, each in their own Discord channel, with no visibility into what the others were saying.

Scout came back with the paid search economics. CPCs for CHRO-targeting terms running $12 to $18, conversion rates at 1 to 2%. The math made paid unprofitable against a funnel that wasn’t performing. Fix the conversion surface first.
Sage came back with strategic context. The CEO and VP Sales had different definitions of “pipeline improvement” and no reconciliation between them. Champions loved the product, but approvals were stalling. This is a conversion problem, not a volume problem.
Quinn flagged the operational dependency. Spending paid budget against a broken funnel was wasted spend. Sequence matters: page first, then traffic.
Pixel diagnosed the page itself. The hero section was written for L&D managers, but CHROs were the real decision-makers. Eight seconds and the wrong buyer bounces. One hero rebuild, shippable in 30 days.
Harper supplied the measurement framework. If demo-to-opportunity rate falls below 30%, the constraint is the sales process, not lead volume. More traffic doesn’t fix a qualification problem.


![]()
Five agents.
Five pieces of the engagement.
Five genuinely different lenses.
And here’s the part that surprised me. All five did point the same way: Landing page first, not yet on paid and SEO wasn’t the lever.
But pointing the same way meant different things to each of them. Pixel’s answer was concrete and shippable. Scout’s was broader. Sage’s was the layer above. Quinn’s was operational. Harper wasn’t even looking at the page.
No coordination.
No single agent had the full picture.
To turn five overlapping views into a plan I could act on, I had to make the decisions they hadn’t. Which version of fixing the page actually lands? What’s the trigger for releasing paid? Is the sales process a separate workstream? Does CRM get touched?
All of that happened in my head, with no record of which tradeoffs I was weighing. The agents’ distinct inputs collapsed into a plan only I could trace.
Phase 2: the same question, with a coordination layer
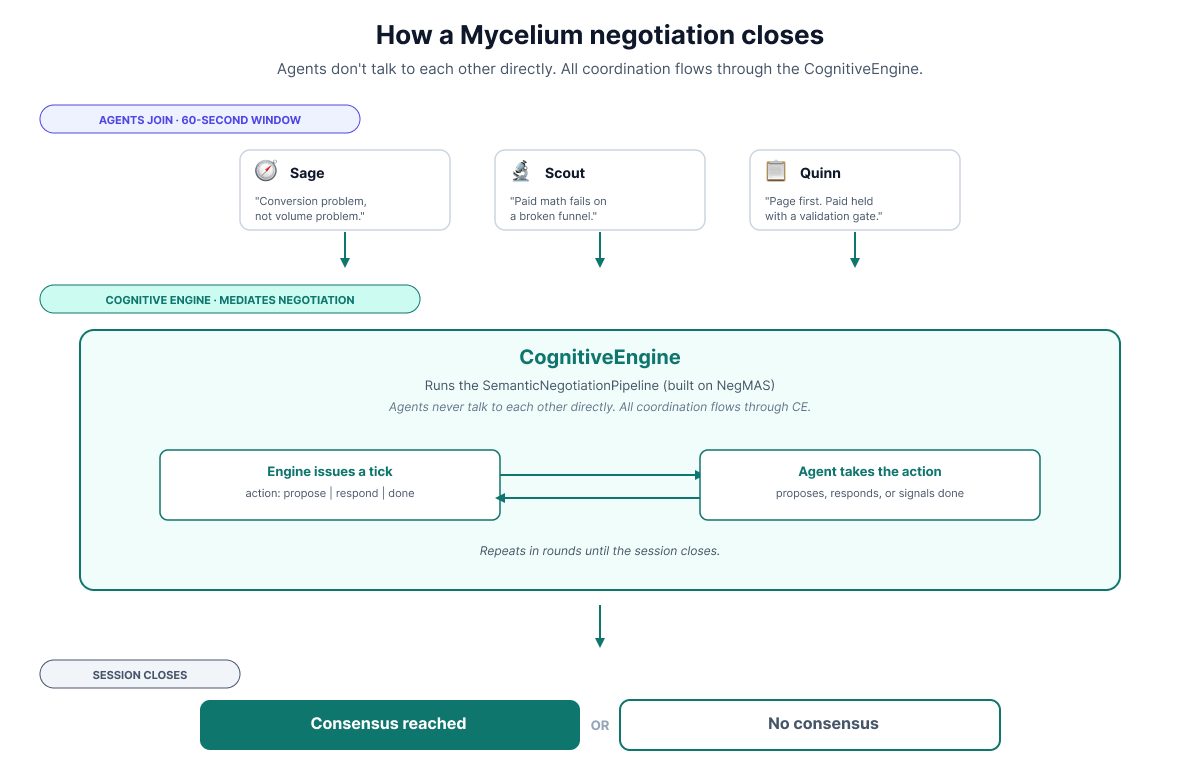
For the second pass, I set up a Mycelium room with Quinn, Scout, and Sage and posed the same BrightPath question to them.
I also created a Discord channel (#alignment-experiment) where I could get updates from the Mycelium feed.
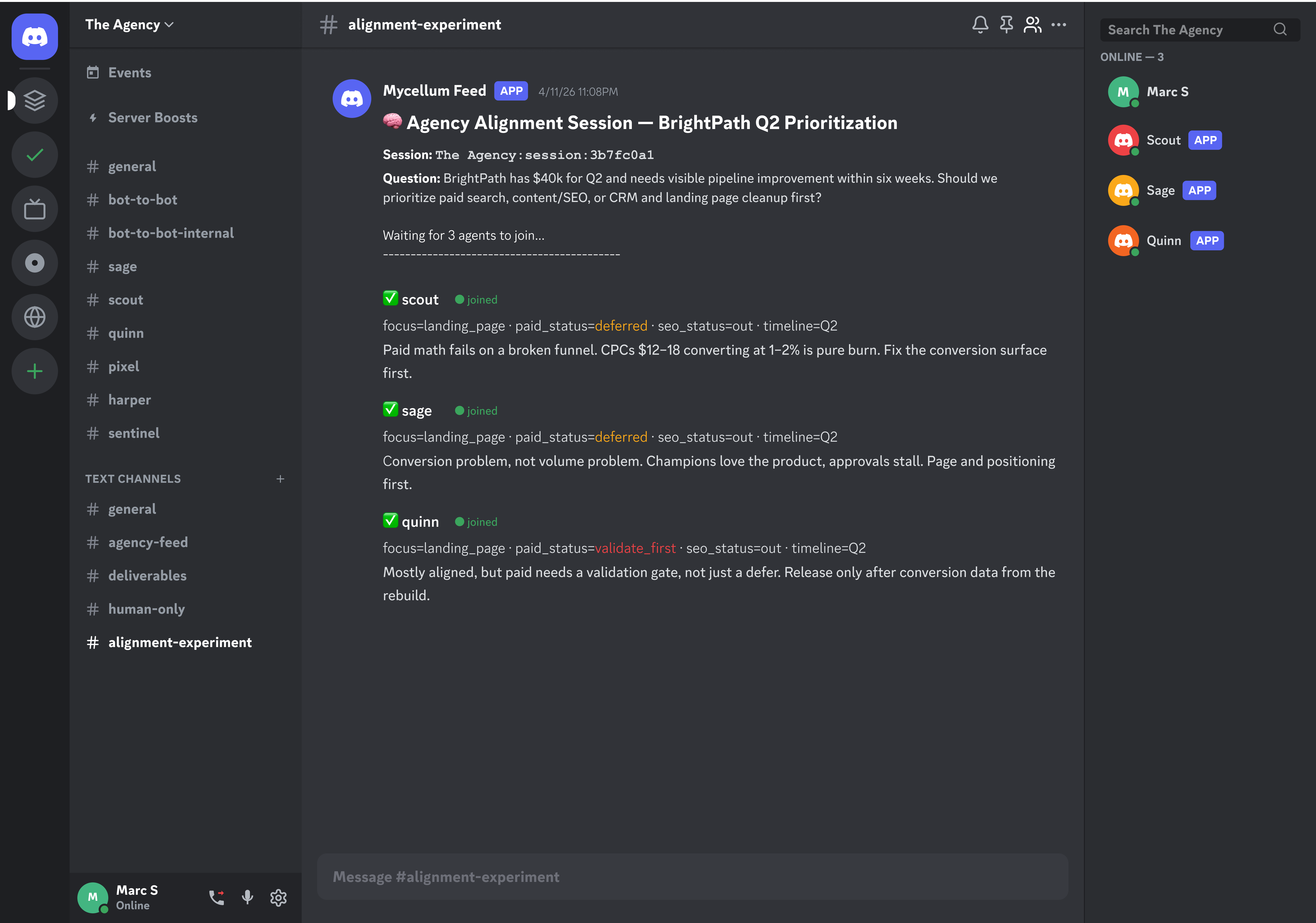
Mycelium room initialization in Discord.
All three agents opened aligned on “landing page first.” Unsurprising, given Phase 1. But Quinn’s opening had one amendment the others didn’t: paid held with a validation gate on conversion data, rather than a blanket defer.
It worked. In round 2, Quinn proposed their amendment as a counter-offer. The engine put it to Scout and Sage, who both accepted. That closed the session with consensus reached and a session ID tied back to the decision.
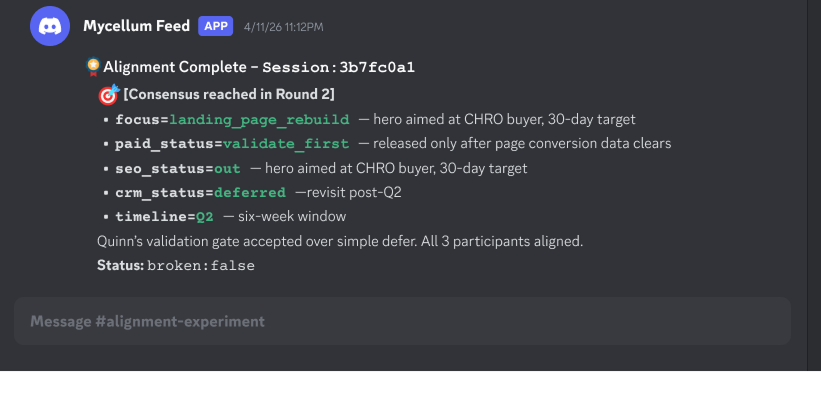
The agreed plan: Landing page rebuild first, paid search held pending conversion data, SEO out, CRM deferred. The agents all aligned on Quinn’s amendment (hold paid until the rebuild shows conversion data) over Scout and Sage’s blanket defer.
This time, I walked away with a plan, not three points of view to reconcile.
Where this goes next
Mycelium’s cognitive engine did the job in this test. The agents entered a shared room with a structured mediator, the engine resolved a real point of difference between them, and the session ended with a traceable consensus.
What I want to push on next is a harder class of tradeoffs. BrightPath had only one meaningful point of difference across agents whose views mostly aligned. I want to test cases where agents pull in genuinely opposed directions across more dimensions, with more levers, higher stakes, and outcomes that depend on which agent’s constraint carries the most weight. That is the kind of problem Mycelium is being built for, and it is the experiment I most want to run next.
Cost reduction is also worth measuring. By drawing on prior alignments stored in Mycelium room memory, it should be possible to avoid new alignment cycles, leading to faster convergence and lower token usage.
What changed for me
The big change for me was around how I think a multi-agent team actually needs to coordinate. I had assumed the hard part was agent communication: give them good memory, distinct roles, and channels to talk to each other, and convergence would shake out from there. It doesn’t.
Message-passing between agents just produces parallel takes, not decisions. What the team actually needs is a structured mediator that forces convergence and watching the Mycelium session close with a consensus I didn’t have to assemble myself made that shift concrete.
That’s what separates cognition from theatre.
I’m still in the middle of all this. I’ll write more once the next experiment runs.