What Running AI Agents on My Mac Is Teaching Me About Enterprise AI
Running local agents has revealed surprising parallels to enterprise deployment challenges — and some lessons that only emerge from hands-on experimentation.

For the past couple of months, I’ve been running OpenClaw locally on a separate Mac mini. I started doing it because I wanted to get closer to the part of agent systems that only really shows up once they have to persist over time.
Agent memory starts to really matter, context management becomes a real constraint. Coordination gets harder. And the whole experience of the system depends on a lot more than whether the model can generate a smart answer.
I wanted a way to test some of my questions directly instead of thinking about them in the abstract. OpenClaw gave me that.
This is a first pass at what I’ve been working on.
A local proving ground
At Outshift, a lot of our work focuses on where agent systems are heading before most organizations are really there yet.
We published our Internet of Agents thesis before multi-agent systems became a normal part of the conversation, and that thinking shaped a lot of what came after, including HAX, our work with AGNTCY, and broader questions around how agents discover each other, exchange context, and operate across systems.
That made this kind of hands-on experimentation especially useful, because it’s a practical way to work through some of those issues before they show up more fully in enterprise settings.
Where it broke
The first thing OpenClaw made obvious was how quickly these systems start to fall apart when memory and context are weak.
Longer threads became unreliable. The agent would lose track of what we had been doing. Important details would get compressed away or dropped entirely. What was supposed to feel persistent often felt fragile.
The OpenClaw project has improved a lot since then. But in the version I started with, the gaps were significant enough that it was hard to use seriously.
That ended up being the useful part, because the failures pointed straight at the real issue. Once agents need to operate over time, the challenge is no longer just getting a good answer in the moment. It becomes a systems problem. What should an agent remember? What should it summarize? What needs to remain available in full detail? What can it safely act on? How do you preserve continuity without letting the whole thing drift off course?
Those are local problems when you are running one setup on a Mac mini. They are also enterprise problems once agent behavior becomes more persistent, more connected, and more operational.
Making it usable
To get OpenClaw into a state where I could actually push it further, I had to spend a lot of time fixing memory and context.
Out of the box, those were the core issues. Once conversations got longer, the system started losing important detail, compressing the wrong things, and dropping enough continuity that trust started to break with it.
So I started changing things.
I built a three-layer memory model: working memory for current tasks and daily notes, episodic memory for session history, and long-term memory for more stable facts, preferences, and reference material. The agent writes to each layer differently and pulls from them differently depending on the situation.
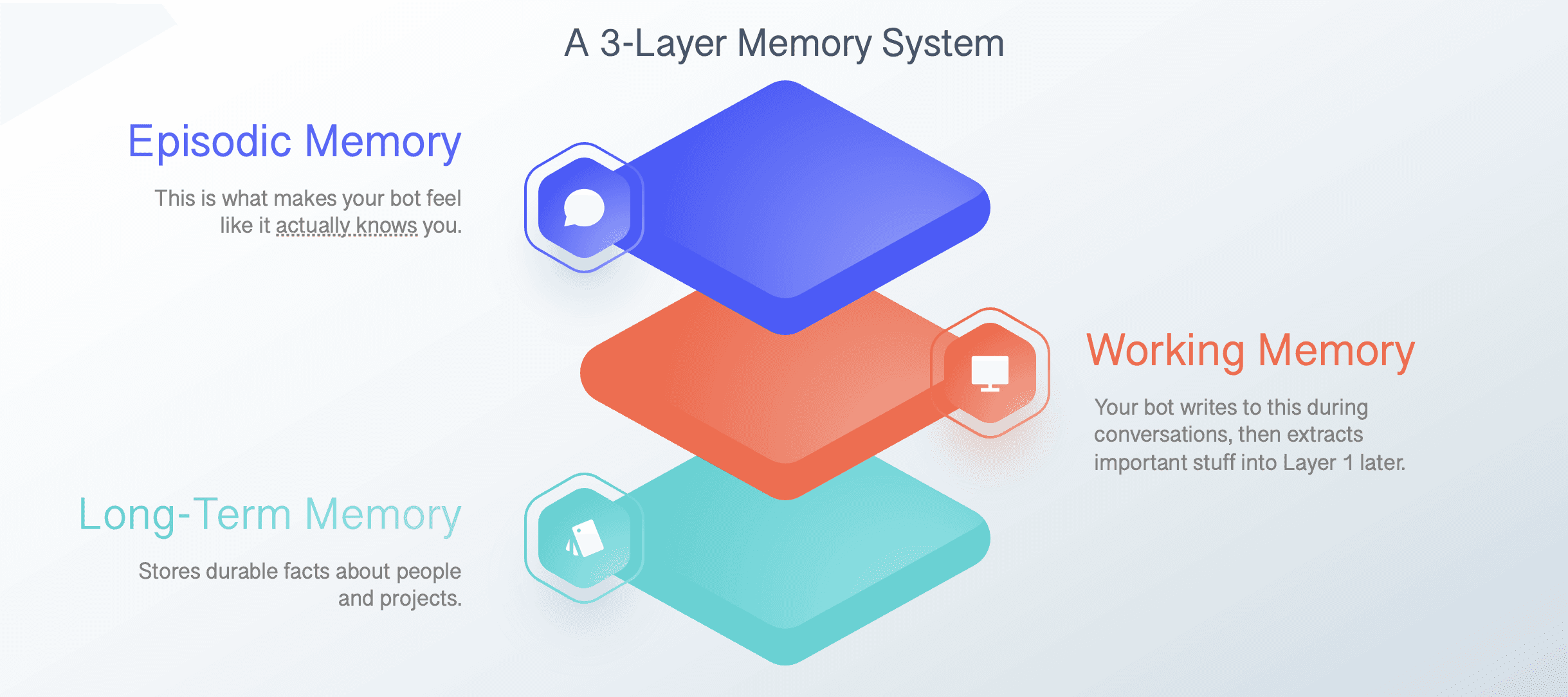
I also implemented LosslessClaw, which let me compress older conversation history into summaries that could still be expanded later when needed. Instead of watching useful context disappear once the window filled up, I could preserve it in a structure that was still accessible.
Then I added a Mac Studio running local models through Ollama, and they gave me more room to work. No API limits, no constant concern about running out of context halfway through a task, and more freedom to let longer workflows play out.
None of this was especially elegant. It was mostly trial and error, frustration, tweaking, and trying again. But once memory and context became more reliable, the system stopped feeling so fragile and started feeling like something I could learn from.
Moving from one agent to many
The more interesting experiments started once I moved beyond a single assistant.
This connected directly to another area we have been working on at Outshift: the Internet of Cognition. The question there is not just whether agents can send messages to each other, but whether they can build enough shared understanding to align on goals, interpret context in similar ways, and produce something more coherent than a chain of handoffs.
To test that, I set up a separate OpenClaw environment as a simulated consulting agency. Seven specialized agents, each with a distinct role and point of view. I ran mock client engagements through the system: intake, framing, strategy, deliverables. Each agent built up its own memory from the vantage point of its role.
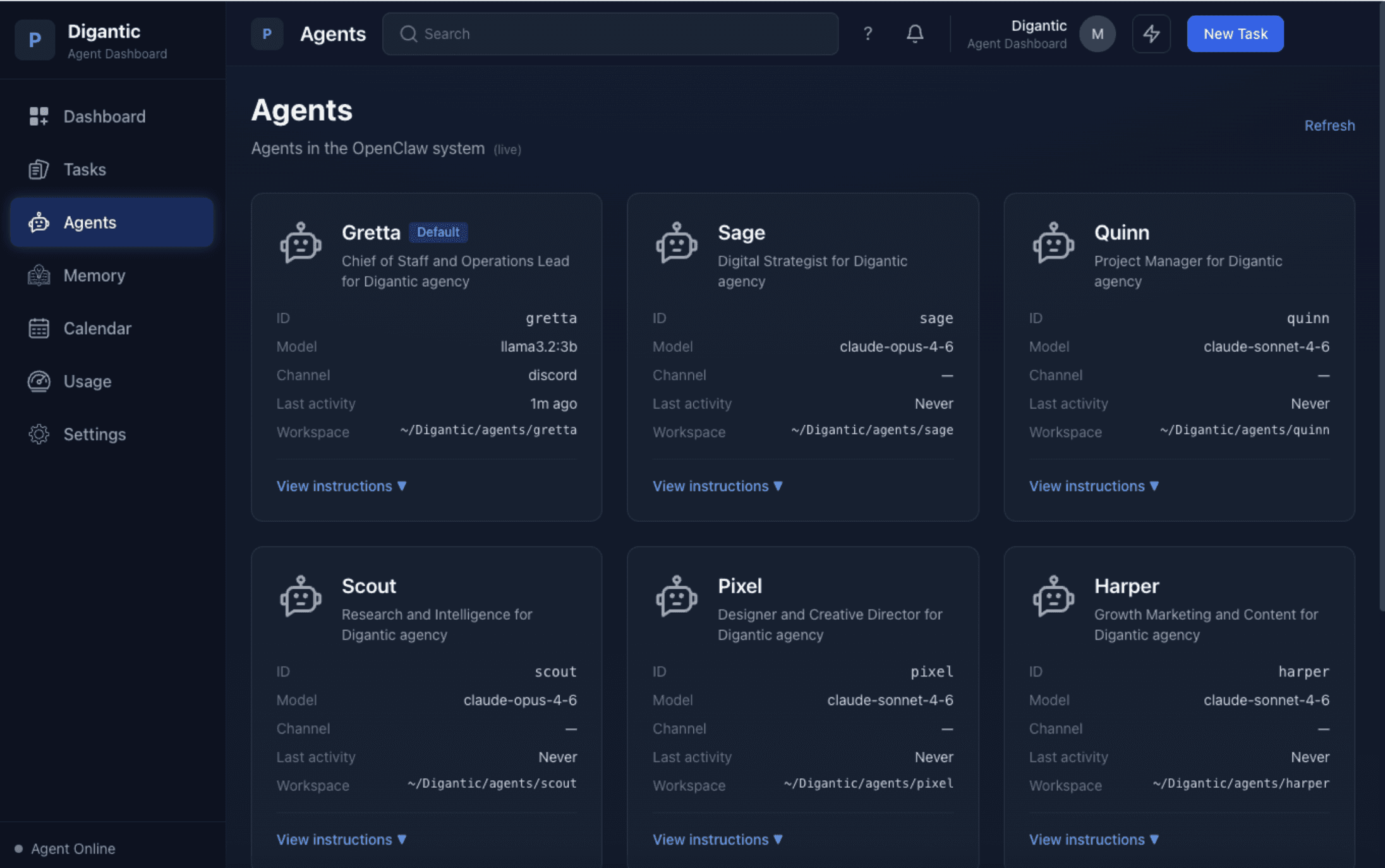
Then I pushed on the part that interested me most. What happens when those agents need to align on a recommendation? What carries over cleanly? What gets distorted? Where does coordination start to crack even when each agent seems competent on its own?
That work deserves its own article, but one thing became clear quickly: message passing is not the same as shared understanding. A group of agents can look coordinated on the surface while still operating from different assumptions, incomplete context, or slightly different goals.
That gap sits close to the center of the recent cognition work we have been doing. Connection matters. Discovery matters. Message exchange matters. But none of that, on its own, creates shared context, aligned intent, or anything we should mistake for real collaboration.
What changed for me
What changed for me most was how quickly memory and context moved from being infrastructure concerns to being the foundation of the experience itself.
A strong model inside a weak memory system still produces a weak experience. An agent that cannot reliably retain, retrieve, or reconstruct the right context is like working on a computer that keeps losing your files.
That also reinforced something I care a lot about as a design leader: human-agent collaboration. When should an agent act on its own? When should it ask? How should it show what it remembered, what it inferred, or why it made a recommendation? How do people correct it without having to rebuild everything from scratch?
The other thing this changed for me is how I think about local experimentation. Running agents on a Mac is obviously not the same as deploying them across an enterprise, but these experiments are not toy versions of the real problem. The same categories of failure show up early: handoff issues, brittle tool use, trust breakdowns, memory gaps, coordination drift, and the slow erosion of continuity once the system starts losing the thread.
And really, some things you only really learn by building. Reading papers helps. Following the space helps. Talking to engineers helps. But there is a difference between hearing that multi-agent systems are hard and watching one fail in a way that exposes the exact assumption you got wrong.
That is what makes this kind of work useful. It compresses the learning, and you get a smaller environment where the structural problems show up faster.
What’s next
I’m still in the middle of this work.
Some of what I changed made these systems more useful. Some of it mostly made the weak spots easier to see. What made working with a local agent framework like OpenClaw so useful was how quickly it turned abstract questions into concrete ones. Memory, context, coordination, trust. They stopped being ideas and became things I had to deal with directly.
I’ll write more soon about the multi-agent consulting experiment and the move toward the Internet of Cognition.
My biggest takeaway from all of this is that once agents start operating over time, the question isn’t just whether they can produce a good answer. It’s whether the system around them is strong enough to keep that answer connected to context, continuity, and human trust.